


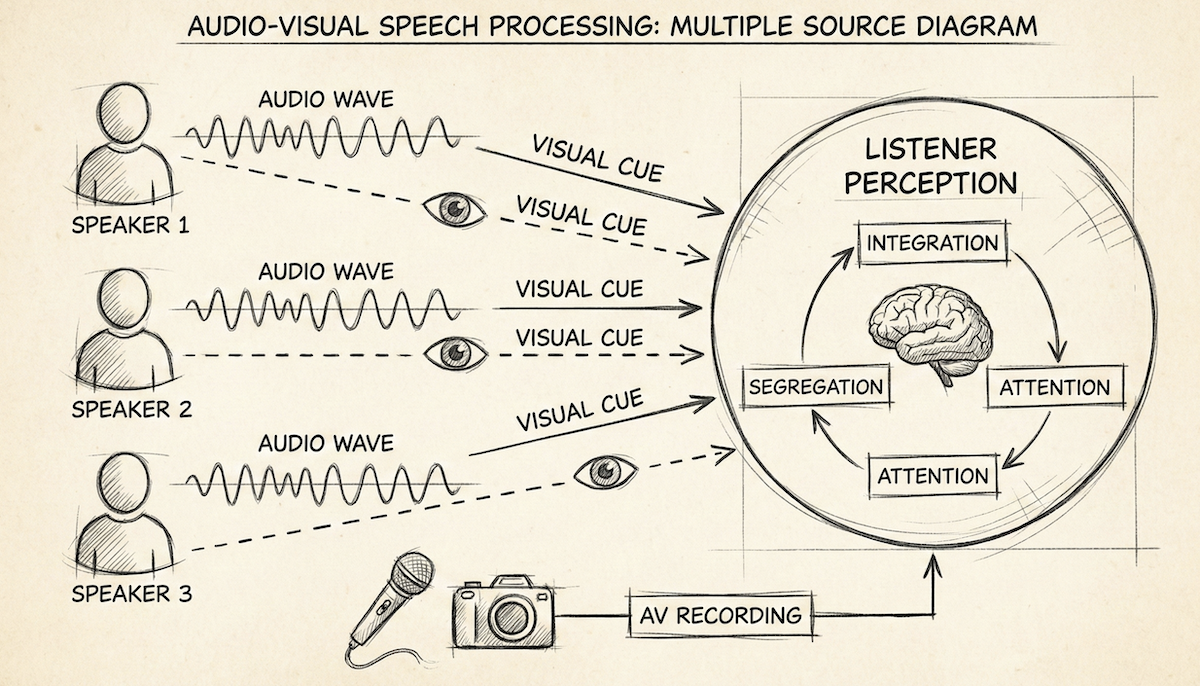
The segments are of varying length, between 3 and 10 seconds long, and in each clip the only visible face in the video and audible sound in the soundtrack belong to a single speaking person. In total, the dataset contains roughly 20 hours of video segments with approximately 40 distinct speakers, spanning a wide variety of people, languages and face poses.
✅ GDPR Compliant
Consent Summary:
All participants provided informed consent for data collection and usage in AI training applications.
Data Collection:
Data was collected through the Boom app phone conversation module with full participant awareness and agreement.
Ethical Considerations:
All data has been anonymized and privacy-preserving measures have been implemented to protect participant identities.


