
In today’s data-driven world, it is more important than ever to have reliable and accurate data management practices. Data versioning plays a crucial role in maintaining data consistency and traceability throughout the data lifecycle. We explore the world of dataset versioning and provide insights into the top-rated data versioning tools available.
What is Data Version Control ?
Data version control or dataset version control is the process of tracking and managing changes made to datasets or files over time. It is particularly essential in organisations where massive amounts of data are generated and manipulated regularly. Proper data version control helps organisations keep track of changes or modifications made to data sets, thereby ensuring reproducibility, auditability, and maintaining a reliable historical record.
Why Dataset Version Control is Crucial for Organizations
Dataset version control helps organisations keep track of different versions of a file or dataset, including different modifications over time. Without data version control, versioning can be cumbersome and error-prone, particularly when different team members are working on the same dataset simultaneously. With data versioning, teams can track who made what changes and when, reducing conflicts and making collaboration more seamless.
Data versioning is also crucial in ensuring proper data management practices. By keeping track of data versions, organisations can easily identify and rectify errors or discrepancies, maintain data consistency, and ensure compliance with data management policies and regulations such Article 12 (Record Keeping) of the upcoming EU AI Act.
Challenges Addressed by Dataset Version Control
Inadequate dataset version control can lead to several challenges for organisations. Some of these challenges include:
- Difficulty tracking data changes
- Increased risk of errors and discrepancies
- Wasted time and resources fixing data-related issues
- Limited traceability of data modifications and versions
- Difficulty collaborating on datasets among team members
With proper data version control techniques and tools, organisations can address these challenges and improve their data management practices.
The Importance of Dataset Versioning
Dataset versioning is an essential aspect of data version control, as it ensures that data remains consistent and traceable throughout its lifecycle. Proper dataset versioning is crucial for reproducibility, auditability, and maintaining a reliable historical record. Here are some of the key reasons why dataset versioning is important:
- Reproducibility: In scientific research and other data-driven fields, being able to reproduce results is critical. With proper dataset versioning, you can always access the exact data used to generate a particular result, making it easier to reproduce that result in the future.
- Auditability: When dealing with sensitive or regulated data, it’s important to be able to demonstrate that the data hasn’t been tampered with. Dataset versioning allows you to track changes to the data over time and maintain a clear audit trail.
- Historical record: Data is often an organisation’s most important asset, and maintaining a reliable historical record of that data is crucial. Dataset versioning allows you to track the evolution of data over time, making it easier to understand how it has changed and why. The EU AI Act has a specific article on Record Keeping that some companies will need to adhere to.
Overall, proper dataset versioning is a key component of effective data management. By maintaining consistent, traceable data throughout its lifecycle, organisations can ensure the reliability and integrity of their data and make better-informed decisions based on that data.
Leveraging Data Versioning Tools
Effective dataset version control is impossible without the right tools. In this section, we will explore some of the most popular data versioning tools and their features. Each of them has its own strengths and weaknesses, so it is essential to choose the right one based on your organisation’s needs.
DVC
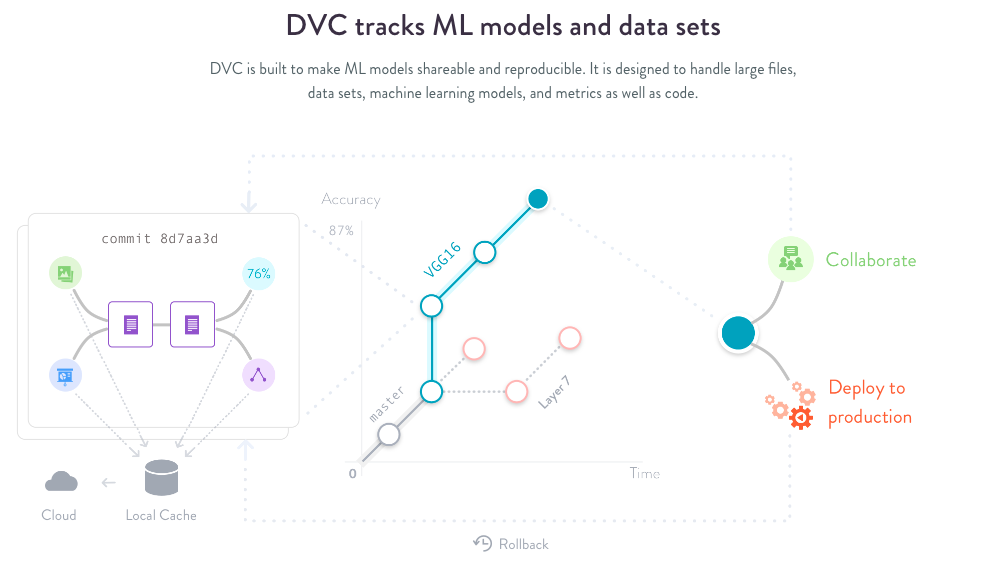
Data Version Control (DVC) is an open-source tool designed specifically for machine learning datasets. It is a lightweight alternative to Git and other version control tools, optimised for managing large datasets. It enables you to define pipelines in any language for complete reproducibility.
When issues arise in a previous model version, DVC saves you time through integrated code, data, and pipeline versioning. Easily share models with teammates using DVC pipelines.
DVC excels at versioning and organising large data sets, with structured and accessible storage. While focused on data and pipeline versioning/management, DVC also offers light experiment tracking abilities.
The core value of DVC is taming ML pipelines for flawless recreation of model versions and seamless collaboration. DVC expands version control to the ML workflow, ensuring models are reproducible and portable.
Neptune
Neptune is a ML metadata store built for teams running many experiments. It enables logging and visualisation of ML metadata like hyperparameters, metrics, videos, visualisations, and data versions. Neptune offers lightweight data versioning combined with robust experiment tracking and model registry. It uses a customizable metadata structure to fit diverse workflows.
Key features:
- Single-line versioning of datasets, models, and other files from local or S3-compatible storage
- Saving of version hash, location, folder structure, and size
- UI for grouping runs by dataset version and tracking artifact changes
- Lightweight data versioning to quickly get started
- Flexible metadata structure to organise experiments as desired
Pachyderm

Pachyderm offers complete version control for end-to-end machine learning pipelines. Available in Community (open source), Enterprise, and Hub (hosted) editions, Pachyderm enables flexible collaboration for any ML project.
As a data versioning tool, Pachyderm provides:
- Continuous data updates to the master branch while experimenting with specific data commits in separate branches
- Support for any file type, size, and volume including binary and plain text
- Transactional, centralised commits
- Provenance tracking to build on others’ work, share and transform datasets, while maintaining a complete audit trail for reproducible results
The key advantages of Pachyderm are full provenance tracking and reproducibility. Teams can seamlessly build on each other’s data and models, branching and merging commits. Pachyderm automatically maintains version history and lineage for complete reproducibility of ML pipelines and results.
WandB
Weights & Biases (WandB) offers lightweight data versioning capabilities to track, visualise, and compare dataset versions used in machine learning experiments.
Key features include:
- Artifact – Upload datasets and record metadata like hashes, sizes, and custom attributes
- Visualisation – See dataset version changes across experiments through WandB’s web UI
- Metadata – Log custom metadata like data splits, source, or preprocessing steps
- Search – Find experiments by dataset version queried by artifact attributes
- Collaboration – Share datasets as artifacts within teams and control access
While WandB provides basic data versioning functionality, it is primarily an experiment tracking and model management platform. For more advanced version control of data and pipelines, systems like DVC or Pachyderm are recommended.
Comet
Comet provides lightweight data versioning and lineage tracking capabilities for machine learning experiments.
Key features include:
- Artifacts – Upload datasets, models, images, etc and record metadata like hashes and sizes
- Visualization – Track artifact versions used in experiments through Comet’s UI
- Integration – Link artifacts from cloud storage like S3, Google Cloud, Dropbox
- Metadata – Log custom attributes like data splits, preprocessing details
- Comparison – Compare artifact metadata and versions across experiments
- APIs – Access artifact metadata through Comet’s API for custom integrations
While Comet covers the basics of data versioning, it does not offer advanced version control systems like DVC or Pachyderm. Comet’s focus is on providing an experiment-tracking platform with built-in support for artifact versioning.
GitLFS
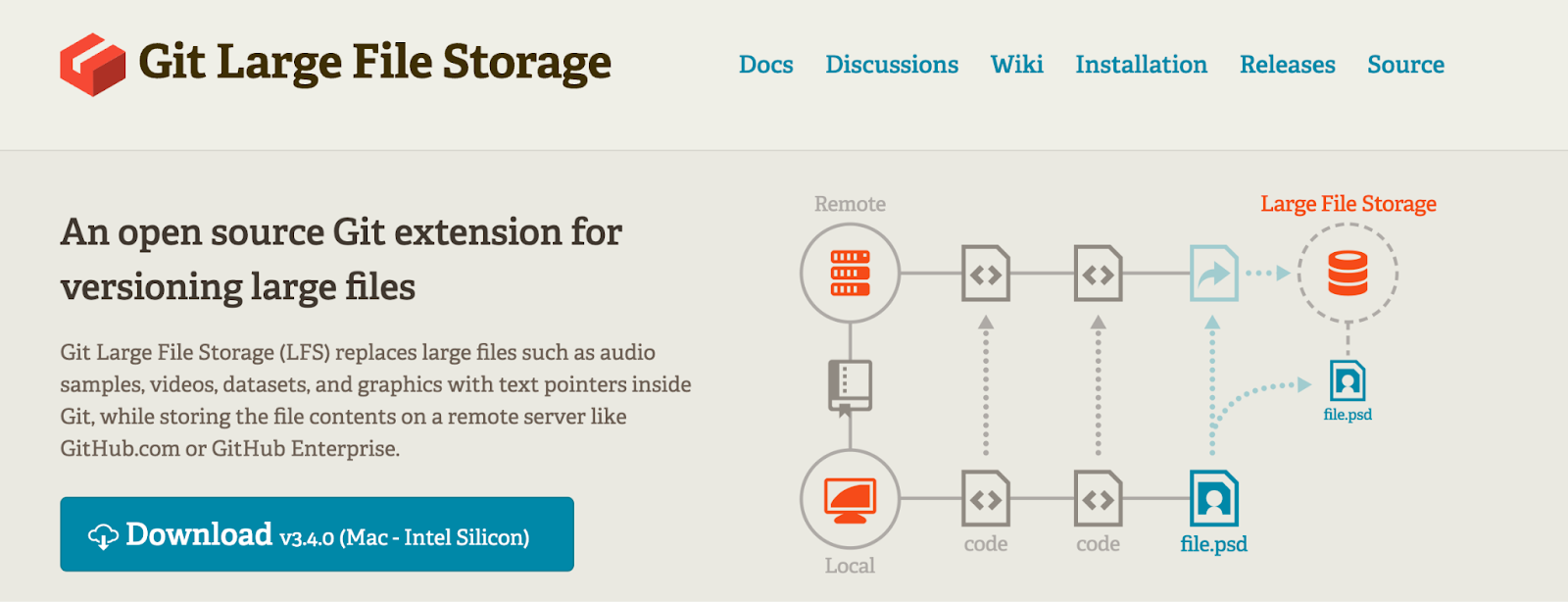
The open-source Git Large File Storage (GitLFS) project is widely used for dealing with large files in Git. It swaps out the bulky audio, video, datasets, and graphics in your repository with slim text pointers, storing the fat file contents remotely on GitHub or GitHub Enterprise.
Developers can version files up to a couple of GB in size and host more large files in repositories by leveraging external storage. Cloning and fetching repositories is faster since large files are stored externally.
Git LFS maintains the same workflow, access controls, and permissions for external large files as regular repository files when used with a remote host like GitHub. This allows developers to seamlessly version large files with the rest of their code.
Explore the top 10 dataset versioning tools preferred by AI Developers and Machine Learning Engineers. Find your perfect tool now!
Getting Started with Data Version Control
If you’re new to data version control, getting started can seem daunting. You may be wondering where to begin, what tools to use, and how to organise your data. In this section, we’ll walk you through the step-by-step process of setting up and implementing data version control for your organisation.
Step 1: Define Your Data Versioning Policy
The first step in implementing data version control is to define your data versioning policy. This policy should outline the versioning protocols, naming conventions, and other guidelines that will govern your data versioning workflows. Establishing a clear and consistent versioning policy will help ensure that your data is organised and easily traceable throughout its lifecycle.
Step 2: Choose Your Data Versioning Tools
There are several data versioning tools to choose from, ranging from open-source solutions to enterprise-grade platforms. Some of the top-rated data versioning tools include GitLFS, Neptune, DVC, WandB and Pachyderm. Consider the features, benefits, and use cases of each tool to find the one that best fits your organisation’s needs.
Step 3: Organise Your Data
Before you start versioning your data, it’s essential to organize it properly. Develop a file structure that makes sense for your organization, and ensure that all data files have clear and descriptive names. Use a data dictionary to document the contents of each file, including information on variable names and data types.
Step 4: Establish Version Control
Once your data is organised, it’s time to establish version control. This involves creating a repository for your data and committing changes to the repository as you make them. Be sure to follow your versioning policy, including naming conventions and other guidelines.
Step 5: Collaborate and Communicate
Effective data version control requires collaboration and communication among team members. Establish clear channels of communication for sharing data and versioning updates, and ensure that all team members understand the versioning policies and procedures. Consider using collaboration tools like Slack or Microsoft Teams to streamline communication.
By following these five steps, you can implement data version control in your organisation and streamline your data management workflows. Remember to always prioritise data integrity and consistency, and don’t hesitate to seek out expert help if you need it. With the right tools and techniques, mastering data version control is within reach.
Ensuring Data Integrity with Version Control
Data integrity is paramount in data versioning. To maintain data accuracy and reliability, you must implement effective techniques and approaches throughout the versioning process. Here are some best practices:
- Validate data changes: Before committing changes, ensure that the data is accurate and complete. Use automated tools, if possible, to perform data validation and error checking.
- Implement error-checking mechanisms: Meticulously monitor your versioning workflows and apply error-checking mechanisms. Use software tools that can alert you when an error occurs or when data backups fail.
- Conduct regular data backups: Data backups are crucial in maintaining data integrity. Back up data regularly and ensure that backups are stored in a secure location.
- Enforce access controls: Limit access to data to only authorised personnel. Implement data access controls, encrypt data, and monitor user activity to prevent data breaches.
- Ensure data privacy: To ensure data privacy, familiarise yourself with data privacy laws and regulations. Use encryption techniques and other security measures to protect sensitive data.
Final thoughts
Mastering data version control is vital in today’s data-driven world. With the right tools and techniques, organisations can ensure data consistency, collaboration, and traceability throughout the data lifecycle.
Implementing the best dataset versioning practices can revolutionise your data management practices.
Embrace the Power of Data Versioning
Effective data version control is not only about the individual efforts of data professionals. Collaborative techniques and strategies for seamless data versioning within cross-functional teams can make a significant difference.
Furthermore, ensuring data integrity throughout the versioning process is crucial. From validating data changes to implementing error-checking mechanisms, maintaining data accuracy and reliability is paramount.
Unlock New Possibilities for Your Data-driven Workflows
By automating your data versioning workflows, you can reduce human errors, improve efficiency, and enable seamless integration with other data management tools. Following a set of data versioning best practices can help ensure the success of your data versioning endeavours.
So, embrace the power of data versioning and start implementing the best dataset versioning practices, and you’ll be one step closer to achieving your goals!


