
The process of object detection involves the identification and recognition of objects in images. A commonly used technique for locating objects is the utilisation of bounding boxes. By training an object detection model, it is possible to identify and detect multiple objects, making it a versatile approach. Object detection plays a crucial role in various computer vision applications, such as self-driving cars, surveillance systems, robotics, and more.
Traditionally, object detection relied on handcrafted features and algorithms like Scale-Invariant Feature Transform (SIFT) and Histogram of Oriented Gradients (HOG). However, with the advent of deep learning and convolutional neural networks (CNNs), object detection has seen significant advancements.
Modern object detection models are trained to detect specific objects and can be used in images, videos, or real-time operations. The models use the unique properties of each object class to identify and locate the required objects. For example, to detect a square shape, the model looks for perpendicular corners, while for a circular object, it searches for central points. Object detection is widely used in applications like face recognition, object tracking, self-driving cars, robotics, and more.
Don’t start empty-handed. Explore our repository of object detection datasets and object recognition video datasets.
Object detection algorithms
1. Histogram of Oriented Gradients (HOG)

The Histogram of Oriented Gradients (HOG) algorithm is a popular feature descriptor used for object detection. It was first introduced in 1986 but gained popularity in computer vision tasks in 2005. HOG extracts essential information from images by calculating gradient orientations in specific regions, such as detection windows. The simplicity of HOG features makes them easily interpretable and computationally efficient.
The architecture of HOG involves dividing the image into smaller cells and calculating gradient orientations within each cell. These gradient orientations are then used to create histograms of orientations. The HOG algorithm has been successful in various object detection tasks, but it has limitations in complex pixel computations and tight object detection scenarios.
Factors to take into account
- Drawbacks – Although the Histogram of Oriented Gradients (HOG) was groundbreaking in the early stages of object detection, it had several flaws. It can be time-consuming for complex pixel calculations in images and is not effective in certain object detection scenarios with limited space.
- When is HOG useful? – HOG should be utilized as the primary method of object detection to assess the performance of other algorithms. Nonetheless, HOG is widely used in most object detection and facial landmark recognition tasks with reasonable accuracy.
- Examples of usage – HOG helps Google Photos categorize and search for specific objects in your photos, like cars or furniture. Tesla’s Autopilot system uses HOG features for pedestrian detection to avoid collisions.
2. Region-based Convolutional Neural Networks (R-CNN)

A technique called “region proposals” was put forth by Ross Girshick et al. in which we extract only 2000 regions (or areas) from the image using a selective search algorithm. It then generates region proposals and then extracts features from these proposals using a CNN. The features are then used for classification and bounding box regression.
R-CNN is one of the pioneering methods for object detection that introduced the concept of region-based convolutional neural networks. It significantly improves object detection compared to HOG and SIFT by utilising selected features and performing more accurate localisation.
Things to take into account
- Limitations – It suffers from slow computation due to the sequential processing of region proposals.
- When is R-CNN Appropriate to Use? – R-CNN, similar to the HOG object detection method, should be utilised as an initial benchmark for evaluating the performance of object detection models. The prediction time for images and objects can take longer than expected, which is why more advanced versions of R-CNN are typically preferred.
- Examples of Use Cases – R-CNN has numerous applications for solving various tasks related to object detection. For instance, it can track objects from a drone-mounted camera, locate text in an image, and enable object detection in Google Lens.
3. Fast R-CNN
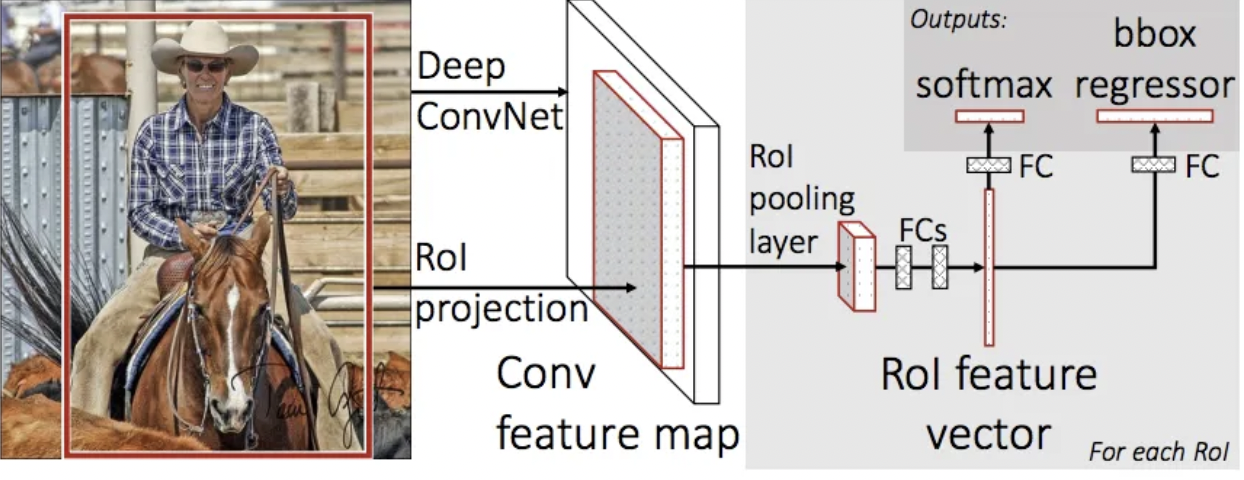
Fast R-CNN is an improvement over the original R-CNN (Region-based Convolutional Neural Networks) method for object detection. It addresses the key drawbacks of R-CNN and SPPnet (Spatial Pyramid Pooling Networks) while improving speed and accuracy. Fast R-CNN combines a region proposal network and a CNN to extract essential features and make predictions for object detection.
The architecture of Fast R-CNN involves passing the entire image through a pre-trained CNN to extract features. A region of interest (RoI) pooling layer is used to align the extracted features with the proposed regions. “Fast R-CNN” outperforms R-CNN since the convolutional neural network doesn’t require 2000 region proposals to be fed to it each time. Instead, a feature map is produced from the convolution process, which is only performed once per image.
Facebook’s DeepFace facial recognition system usesFast R-CNN to achieve high accuracy in recognizing faces in images and videos
4. Faster R-CNN
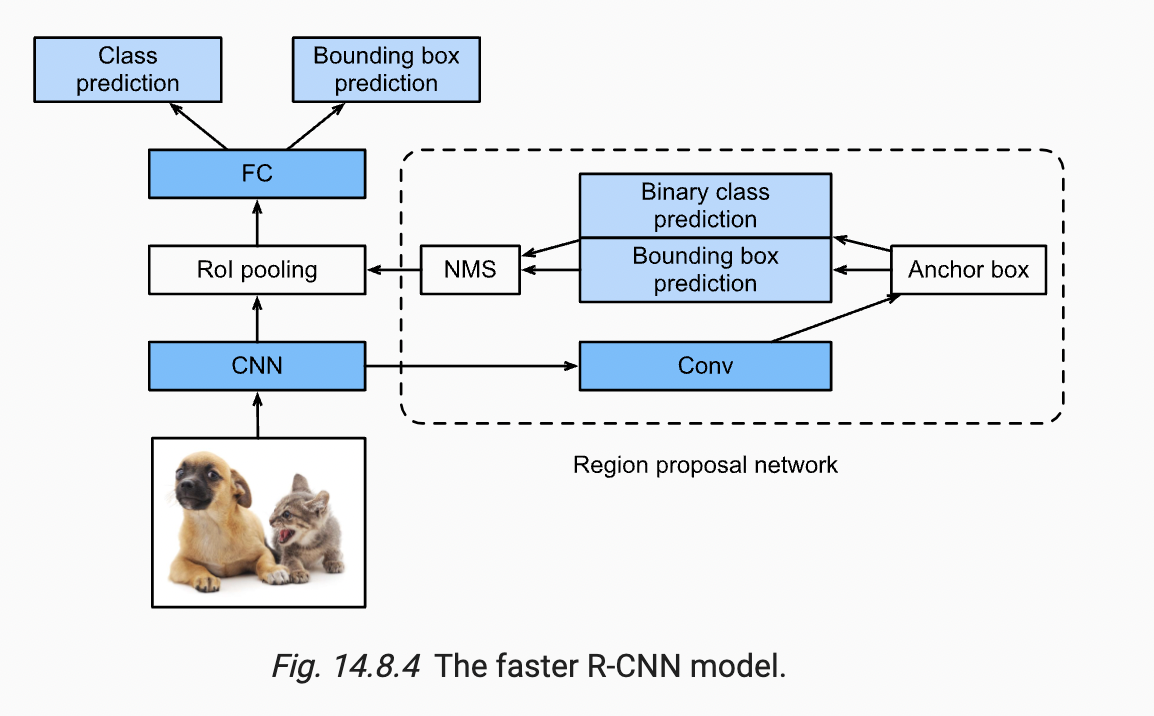
Faster R-CNN is an advanced variant of the R-CNN family that offers significant speed improvements. It replaces the selective search algorithm used in R-CNN and Fast R-CNN with a region proposal network (RPN).
The network’s performance is impacted by the slow and time-consuming operation of selective search. As a result, Shaoqing Ren et al. developed an object detection technique that allows the network to learn the region proposals while doing away with the selective search algorithm.
In this, the image is fed into a convolutional network, which generates a convolutional feature map, much like Fast R-CNN does. A different network is utilised to forecast the region proposals rather than utilising a selective search technique on the feature map to find the region proposals. After using an ROI pooling layer to reshape the projected region proposals, the image inside the proposed region is classified and the bounding box offset values are predicted.
Factors to take into account
- Limitations: One of the primary limitations of the Faster R-CNN approach is the delay in identifying different objects, which is influenced by the type of system being utilised.
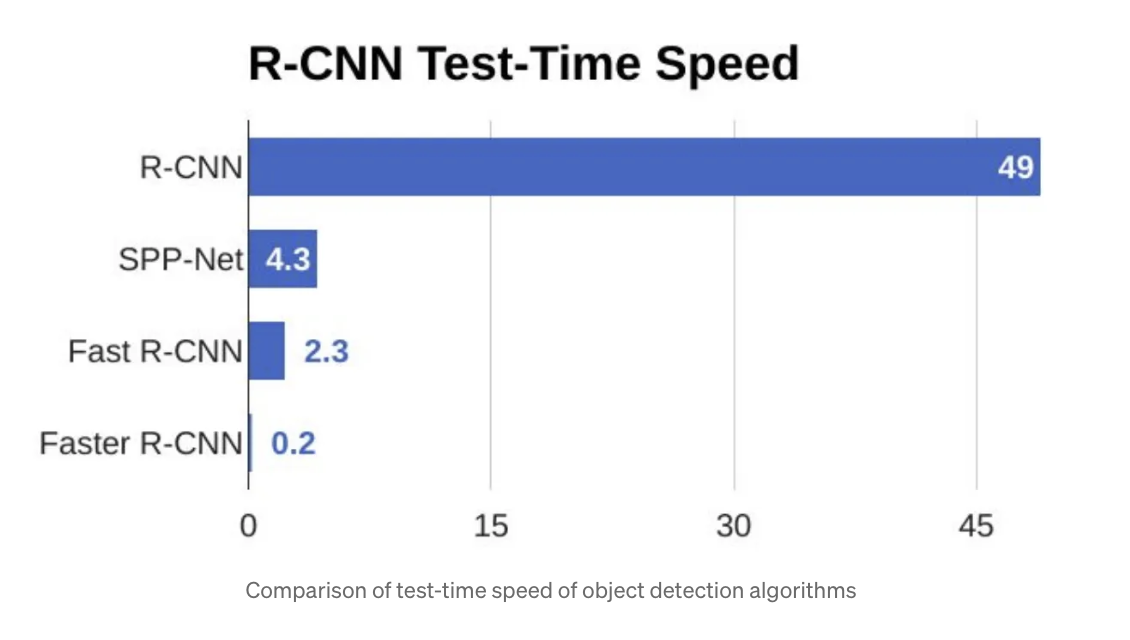
- When is it used? Faster R-CNN is best suited for scenarios where quick prediction time is crucial. While R-CNN typically takes 40-50 seconds to predict objects in an image, Fast R-CNN only takes 2 seconds, and Faster R-CNN can achieve optimal results in just 0.2 seconds.
- Examples of use cases: Security cameras and systems from companies like Hikvision and Dahua leverage Faster R-CNN for object detection and anomaly detection in surveillance footage.
5. Single Shot Detector (SSD)
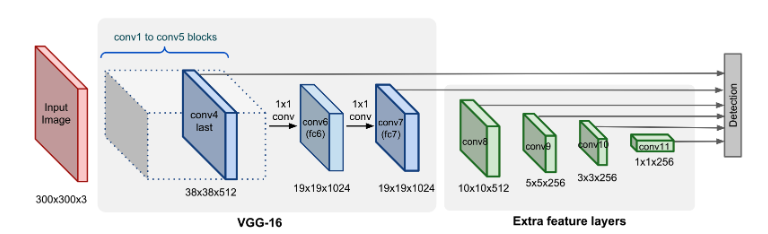
The SSD (single-shot detector) is a rapid method for multi-box predictions that allows for real-time computation of object detection tasks. Although Faster R-CNN techniques can produce accurate predictions, their overall process is time-consuming, with a real-time task taking approximately 7 frames per second, which is not ideal.
The problem of low frame rates compared to the Faster R-CNN model is addressed by the single-shot detector (SSD), which increases the frames per second by nearly five times. This is achieved by eliminating the need for a region proposal network and utilising multi-scale features and default boxes. SSD incorporates all computations in a single network, eliminating the need for intermediate stages like proposal generation or pixel resampling.
SSD is particularly useful for detecting larger objects, where speed is prioritised over precise localisation. It offers competitive accuracy compared to other methods that use separate object proposal stages.
Snapchat leverages SSD for real-time object detection in their face filters and lenses, ensuring smooth and accurate tracking of facial features.
6. You Only Look Once (YOLO)
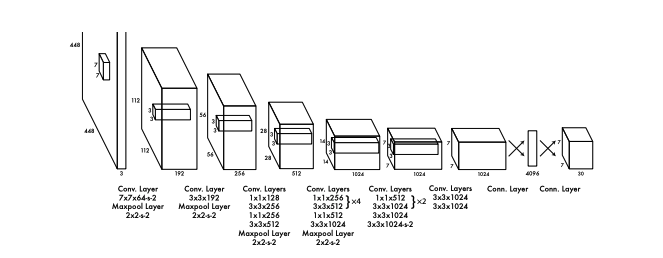
You Only Look Once (YOLO) is a popular object detection algorithm known for its real-time processing capabilities. The YOLO model analyses images at an impressive rate, processing multiple frames per second while achieving high accuracy. YOLO eliminates background errors commonly found in other approaches, resulting in accurate and efficient object detection.
The YOLO algorithm utilises residual blocks, central points, and Intersection over Union (IOU) calculations to achieve its speed and accuracy. However, YOLO may struggle with detecting small objects and precise localisation. Nonetheless, YOLO remains popular for real-time object detection tasks due to its overall high accuracy and speed.
Things to Keep in Mind
- When is YOLO Appropriate? – While the previously mentioned techniques are effective for both image and video analysis in object detection, the YOLO architecture is a top choice for real-time object detection. It can achieve high accuracy and decent speed depending on the device used.
- Common Applications – smart home security companies like Ring and Google Nest leverage the YOLO-inspired model for object detection in doorbell cameras and other security devices, offering real-time alerts and monitoring capabilities.
7. RetinaNet
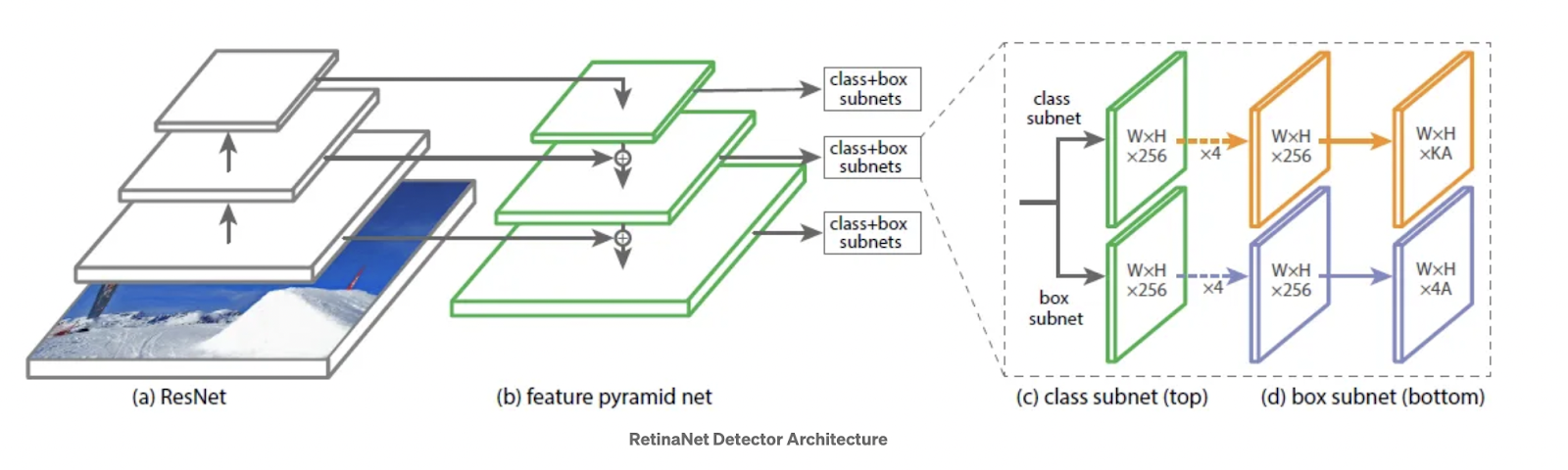
RetinaNet is a state-of-the-art object detection model known for its single-shot object identification capabilities. It surpasses other object detection algorithms in terms of speed and accuracy. RetinaNet replaces the traditional cross-entropy loss with focal loss, which handles class imbalance issues commonly faced by other methods like YOLO and SSD.
The architecture of RetinaNet combines the power of a ResNet model, a feature pyramid network (FPN), and focal loss. The feature pyramid network combines high-resolution features with semantically rich features, enabling accurate object detection across different scales. RetinaNet is widely used for object detection in various domains, including satellite imagery analysis.
Factors to take into account
- When is RetinaNet suitable to be used? Currently, RetinaNet is considered one of the most effective techniques for detecting objects in various tasks. It can serve as an alternative to single-shot detectors and deliver precise and speedy outcomes for images.
- Examples of potential uses – Self-driving technology firm Pony.ai claims to leverage RetinaNet for 3D object detection in urban environments, aiming to enhance their autonomous driving systems.
8. Spatial Pyramid Pooling (SPP-net)
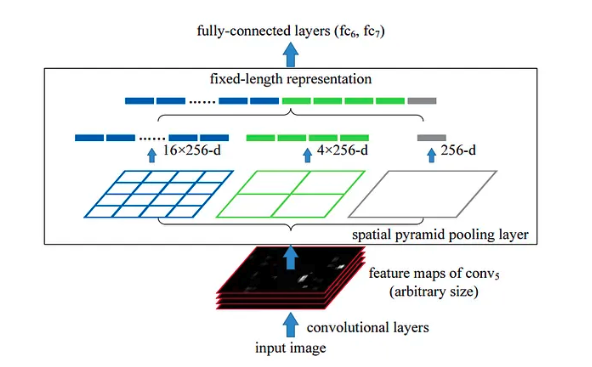
SPP-net is a network topology that provides fixed-length representations for images, independent of their dimensions or scale. It pools features in arbitrary regions after computing feature maps from the entire image. SPP-net is resistant to object deformations and enhances the performance of CNN-based image classification algorithms.
SPP-net is often used for training detectors by creating fixed-length representations for variable-sized images. It has been successful in improving the performance of object detection models. However, SPP-net has been overshadowed by more recent advancements in object detection algorithms.
Open-source Object Detection Libraries
To facilitate the development of object detection projects, several open-source libraries provide pre-built implementations of object detection algorithms. These libraries offer a wide range of functionalities and can be easily integrated into existing applications.
1. ImageAI
ImageAI is a user-friendly Python library that simplifies object detection tasks. It provides a comprehensive set of computer vision algorithms and deep learning methodologies for image recognition, object detection, video analysis, and more. ImageAI supports both pre-trained models and custom training for specific tasks.
2. Mmdetection
Mmdetection is a free, Python-based object detection suite that allows developers to create custom object detection architectures. It provides a modular framework for assembling different components of the detection pipeline. Mmdetection is part of the OpenMMLab project, which aims to provide comprehensive resources for various computer vision tasks.
3. GluonCV
GluonCV is a powerful library framework for deep learning models in computer vision. It offers state-of-the-art implementations of various object detection algorithms, along with a wide range of training datasets and tutorials. GluonCV supports both MXNet and PyTorch, providing flexibility for developers to choose their preferred deep learning framework.
4. YOLOv3_TensorFlow
YOLOv3_TensorFlow is an implementation of the YOLO architecture for object detection in TensorFlow. It offers fast GPU computations, efficient data pipelines, weight conversions, and shortened training periods. YOLOv3_TensorFlow provides a convenient way to leverage the capabilities of YOLO for object detection tasks.
5. Darkflow
Darkflow is a TensorFlow implementation of the darknet framework, which is used for object detection. It provides a Python interface for the darknet model, making it accessible to a broader range of developers. Darkflow supports various tasks such as annotation parsing, network design, model training, and real-time or video detection.
6. Detectron2
The Detectron2 library, created by the AI research team at Facebook’s FAIR, is widely regarded as an advanced framework that is capable of supporting the latest detection techniques, object detection methods, and segmentation algorithms. Built on PyTorch, the Detectron2 library offers great flexibility and scalability, offering a variety of top-notch algorithms and techniques. Furthermore, it is suitable for various applications and has been utilised in numerous production projects at Facebook.
Final Thoughts
The task of identifying objects remains a crucial aspect of deep learning and computer vision, even to this day. There have been significant developments and progress in the methods used for object detection.
The use of algorithms, such as the Histogram of Oriented Gradients, dates back to 1986 when it was first introduced for basic object detection with a satisfactory level of precision. Today, more advanced architectures such as Faster R-CNN, SSD, YOLO, and RetinaNet have been developed.
Object detection is not only applicable to images but it can also be effectively used on videos and live footage with great precision. In the coming years, we can expect to see numerous advanced algorithms and libraries for object detection.


