
Reinforcement learning from human feedback (RLHF) is a fascinating concept that bridges the gap between artificial intelligence (AI) systems and human expertise. In this article, we explore the meaning of RLHF and delve into how it works. Whether you are new to the field or an experienced AI engineer, this article will provide you with a step-by-step understanding of RLHF and its applications.
Understanding the basics of reinforcement learning
Before diving into RLHF, it is crucial to grasp the fundamentals of reinforcement learning (RL). RL is a subfield of AI that focuses on training agents to make intelligent decisions through trial and error. In RL, an agent interacts with an environment and receives feedback in the form of rewards or penalties based on its actions. Through this iterative process, the agent learns to maximise its rewards over time by finding an optimal policy.
For example, Google’s search algorithm leverages reinforcement learning to optimise search results. The Google search algorithm acts as the agent, with the search results page and user behaviour as its environment. The algorithm experiments with ranking pages differently for a search query. The feedback or reward is user engagement metrics like bounce rates, time spent on the site and clicks. This enables the algorithm to learn to rank pages for maximum user satisfaction through iterative reinforcement learning driven by real user interactions.
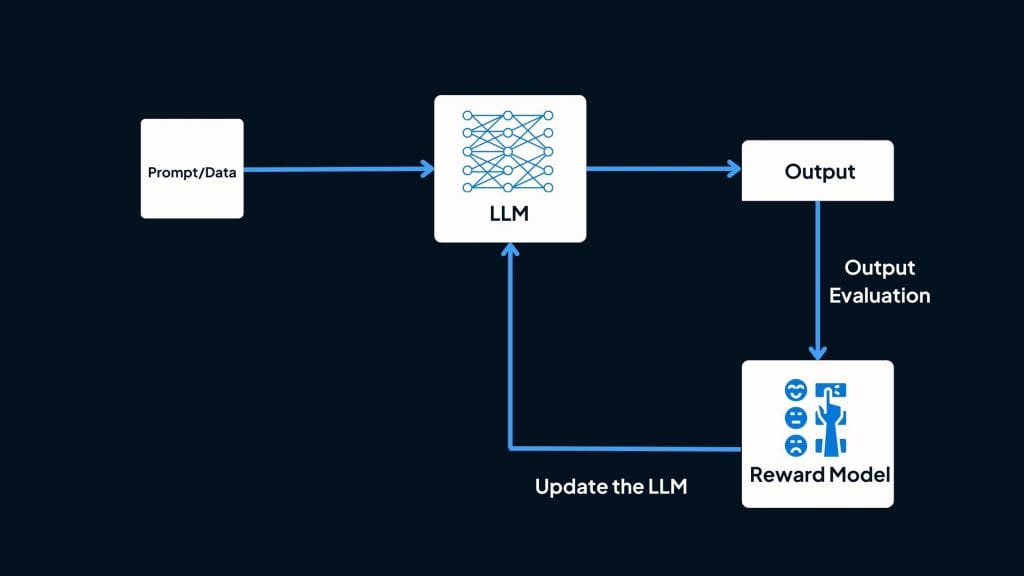
What is RLHF and how does it differ from traditional reinforcement learning?
RLHF builds upon the foundation of RL by incorporating human expertise and feedback into the learning process. In traditional RL, an agent learns solely from the rewards provided by the environment. However, RLHF introduces the concept of human feedback, which allows the agent to learn from the knowledge and insights of human experts. This integration of human feedback enables AI systems to benefit from the collective intelligence and experience of humans, leading to more efficient and effective learning. For example, in a medical image recognition model, it would be prudent to have expert radiologists review medical images to give their input. The AI model can learn from this human input.
The importance of human feedback in RLHF
Human feedback plays a pivotal role in RLHF as it provides crucial information that may not be directly captured by environmental rewards. While rewards guide the agent toward the desired outcome, human feedback adds a layer of expertise that helps the agent navigate complex scenarios. For instance, in a game of chess, a reward-based RL agent might learn to win games, but with human feedback, it can acquire strategies and tactics that would have taken countless iterations to discover independently. Incorporating human feedback enhances the learning process, making it faster and more reliable.
How RLHF works – step-by-step guide
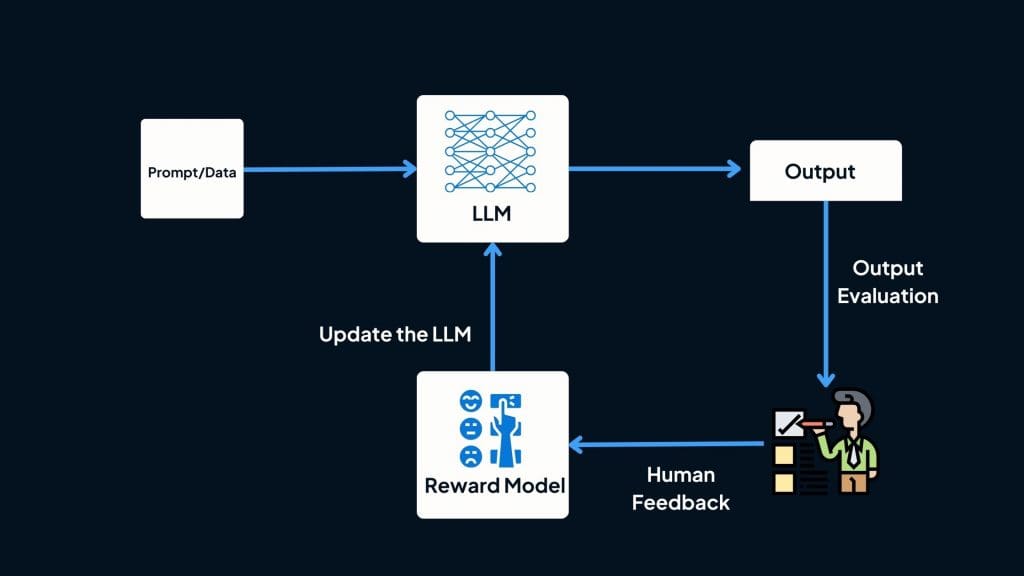
Now that we have a solid understanding of RLHF and its significance, let’s explore how it works in a step-by-step manner:
- Data collection: The agent interacts with an environment and takes actions within it, like moving objects or having a conversation. The human observer can see the agent’s behaviour and environment state.
- Human feedback acquisition: The observer provides evaluative feedback on the agent’s actions, indicating whether they are good or bad, but not demonstrations of correct behaviour. Common forms of feedback are ratings, comparisons, and corrections. The feedback serves as additional information for the agent to refine its learning process.
- Reward model integration: The next step is to combine the environmental rewards with the human feedback. The agent has a reward model that interprets the human feedback as a reward signal, estimating which actions led to positive or negative judgments from the human. This integration facilitates a comprehensive learning process where the agent can optimise its actions based on both intrinsic rewards and human-guided feedback.
- Policy update: Using the collected data, human feedback, and reward models, the agent updates its policy to improve its decision-making abilities. This update involves adjusting the weights and parameters of the AI system to align with the desired outcomes.
- Iteration and improvement: The RLHF process is an iterative one, where the agent continues to collect data, acquire human feedback, integrate rewards, and update its policy. Through these iterations, the agent gradually improves its performance and decision-making capabilities.
How ChatGPT uses RLHF,
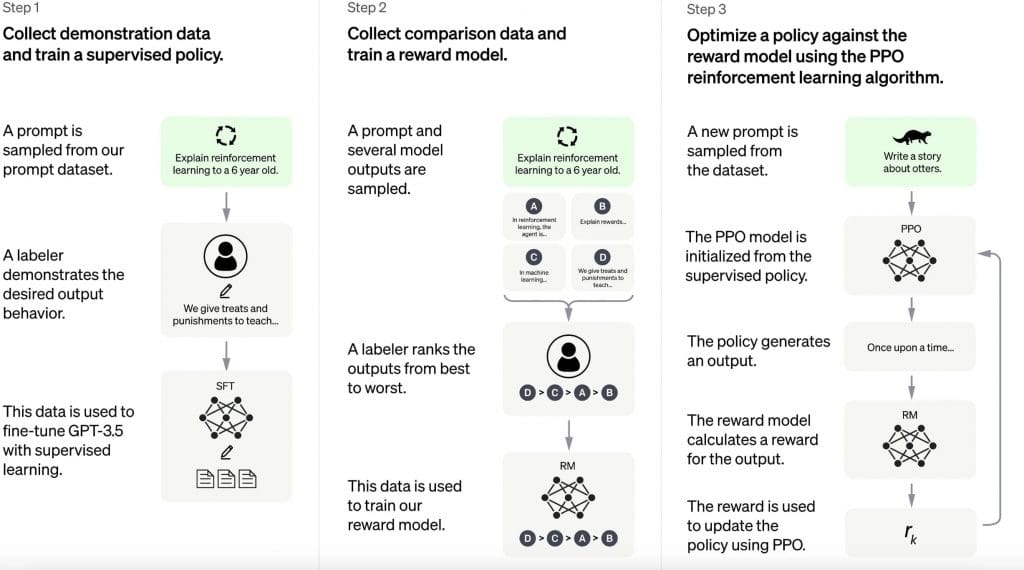
Looking to Leverage RLHF for Large Language Models? Our Experts Can Help.
Benefits and challenges of using RLHF in AI systems
Using RLHF in AI systems offers several benefits, including:
- Faster learning: Incorporating human feedback accelerates the learning process, enabling AI systems to achieve desired outcomes more swiftly.
- Improved performance: RLHF enhances the decision-making abilities of AI systems, leading to improved performance and accuracy in various tasks.
- Domain expertise integration: Human feedback allows AI systems to leverage human expertise and insights, making them more robust and adaptable in complex scenarios.
However, there are also challenges associated with RLHF:
- Expert availability: Acquiring human feedback requires the availability of domain experts, which may not always be feasible or cost-effective. However, Twine AI provides access to half a million human experts across many fields who can provide high-quality, relevant feedback to reinforce AI learning.
- Feedback quality: Ensuring the quality and consistency of human feedback can be challenging, as it relies on the expertise and subjective opinions of individuals. For feedback quality, Twine AI has rigorous processes to train, evaluate, and monitor our experts. This maintains reliable, high-quality feedback. We also synthesise perspectives from multiple experts to smooth out individual subjectivity.
- Ethical considerations: RLHF raises ethical concerns regarding the responsibility and accountability of AI systems when learning from human feedback. Ensuring fairness and avoiding biases becomes crucial in the development and deployment of RLHF-based AI systems. At Twine AI, we rigorously uphold ethical AI practices in our workflows. We provide oversight on feedback usage, preemptively test for harm, and maintain explainability. This enables safe, unbiased AI that aligns with human values as it learns from human guidance.
With Twine AI, you can implement principled RLHF that upholds human values. Contact our experts today to learn more.
RLHF in industry and real-world scenarios
RLHF finds applications in various industries, including healthcare, robotics, gaming, and personalised recommendation systems. Let’s explore a few examples to understand the practical implications of RLHF:
- Autonomous vehicles: RLHF can be used to train self-driving cars to navigate complex road conditions by leveraging human expertise and feedback.
- Game development: Developers can incorporate RLHF to create intelligent non-player characters (NPCs) that learn from human players, providing a more immersive and challenging gaming experience.
- Customer service: RLHF can improve chatbots and virtual assistants by learning from customer interactions and feedback, enhancing their ability to understand and respond to user queries.
- Medical diagnosis: RLHF can be utilised to train AI systems to assist doctors in diagnosing complex medical conditions. By incorporating human medical expert feedback, the AI system can learn to analyse medical data and provide accurate diagnoses, improving patient outcomes.
- Robotics and automation: RLHF enables robots and autonomous systems to learn from human guidance and perform complex tasks efficiently. For instance, a robotic arm can learn to manipulate objects by combining environmental rewards with human feedback on optimal grasping techniques.
- Content recommendation: By integrating RLHF, content recommendation systems can provide more personalised and relevant suggestions to users. The system can learn from user feedback and adjust its recommendations to align with individual preferences, improving user satisfaction.
Resources and tools for learning more about RLHF
To dive deeper into RLHF and explore its applications, here are some valuable resources and tools:
- Online courses: Platforms like Coursera and Udacity offer courses on reinforcement learning and AI, providing in-depth knowledge and practical insights into RLHF.
- Research papers: Stay updated with the latest advancements in RLHF by exploring research papers published in conferences and journals such as NeurIPS and ICML.
- Open-source libraries: Frameworks like TensorFlow and PyTorch provide RL libraries and toolkits that can be used to experiment with RLHF algorithms and build AI systems.
Final Thoughts
Reinforcement learning from human feedback (RLHF) combines the power of AI systems with human expertise to create more intelligent and efficient learning algorithms. By understanding the meaning of RLHF and its step-by-step process, we can show its potential in various domains, from healthcare to robotics. While RLHF presents benefits and challenges, its integration in real-world scenarios is transforming industries and paving the way for more advanced AI systems. Embracing RLHF opens up endless possibilities for innovation and collaboration between humans and machines.


