
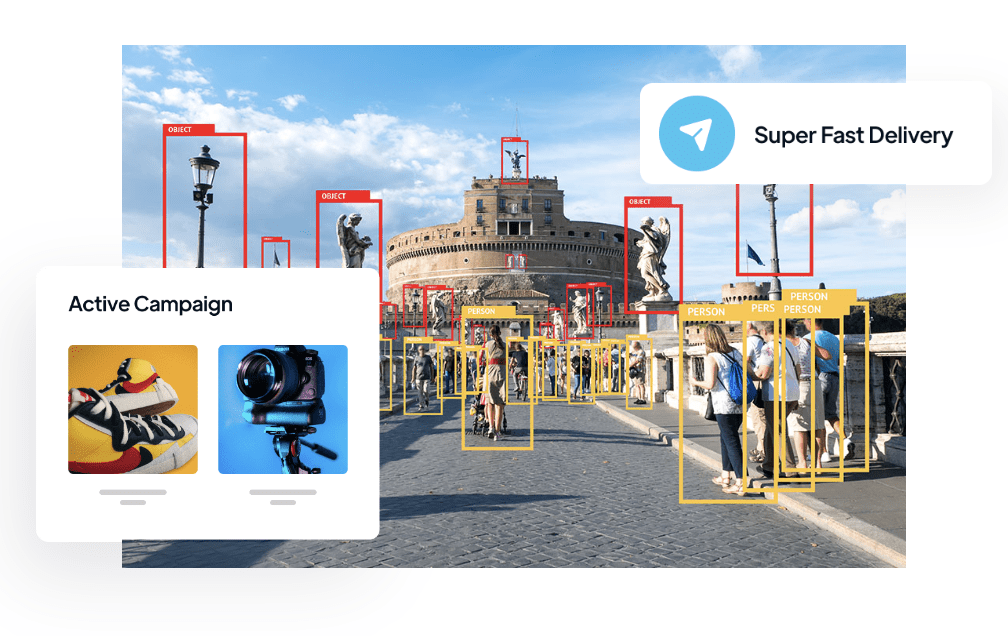
What is image annotation?
Image annotation is the process of labeling or identifying particular objects or regions inside an image. By adding data annotations to photos, we provide computers particularly AI algorithms, the ability to understand and analyze visual information. This enhances their object detection, image recognition, and segmentation abilities.
Machine learning algorithms are built around annotated images because they supply the “ground truth” information which is essential to make it work. With the use of this data, the models may learn to recognize patterns, shapes, and other properties in photos, ultimately enabling precise analysis and forecasting. The effectiveness and dependability of computer vision models are substantially hampered by poor image annotation.
Importance of image annotation in computer vision
Image annotation is of critical importance in the computer vision sector as it enables machines to understand and interpret visual data. By annotating images, we provide the necessary context and labels for computer vision algorithms to learn and make accurate predictions. Whether it’s identifying objects for autonomous vehicles, detecting anomalies in medical imaging, or recognizing faces in security systems, image annotation is the key to computer vision AI technology.
Types of Image Annotation Techniques
There are several types of image annotation techniques that serve different purposes in computer vision tasks:
1. Bounding Box Annotation
Bounding box annotation involves drawing rectangles around objects of interest within an image. This technique is commonly used for object detection tasks, where the goal is to locate and classify objects accurately within an image. Bounding box annotation provides the coordinates and dimensions of the object, enabling the computer vision model to accurately identify and localize it.

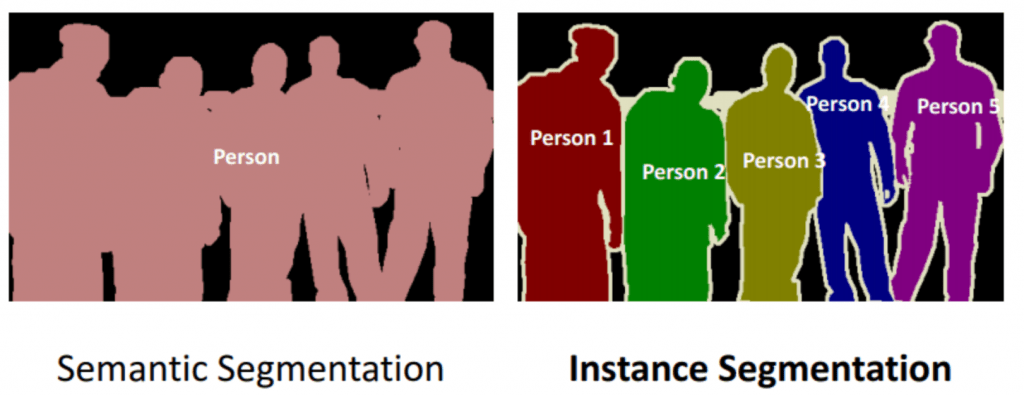
2. Semantic Segmentation
Semantic segmentation involves labelling each pixel within an image with a corresponding class or category. This method is used for tasks such as image recognition and scene understanding, where the goal is to classify and segment different objects or regions within an image. Semantic segmentation enables precise identification and separation of various elements within an image, contributing to improved accuracy in computer vision models.
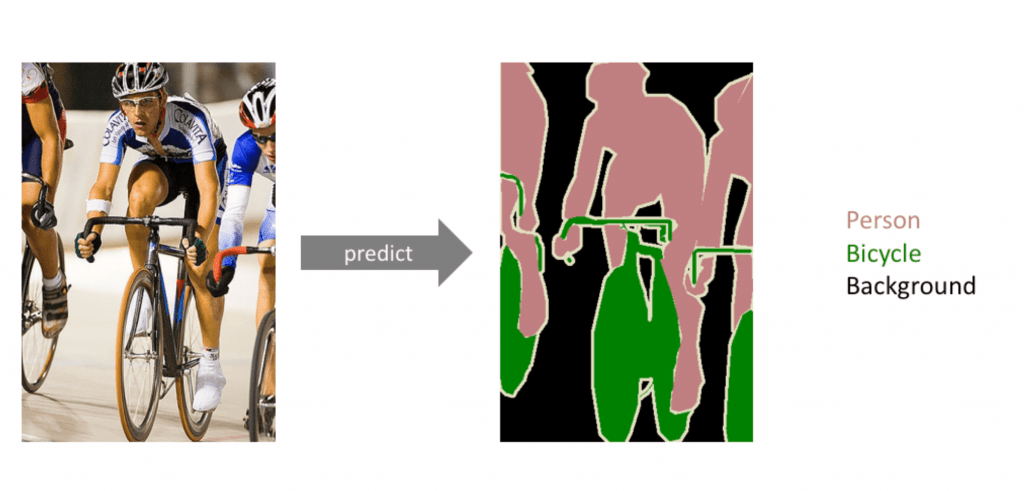
3. Instance Segmentation
Instance segmentation goes a step further than semantic segmentation by not only labeling pixels but also differentiating between multiple instances of the same object. This technique is useful when the distinction between individual objects is necessary, such as counting cells in medical imaging or tracking multiple objects in surveillance videos.
4. Keypoint Annotation or Landmark Annotation
Landmark annotation, commonly known as keypoint annotation, involves identifying and marking specific key points or landmarks within an image. This method is commonly used in facial recognition and pose estimation tasks, where the goal is to accurately locate and identify key points on a face or body. To visualise this, think of the body suits that actors wear for CG characters – well it’s this in reverse. Landmark annotation provides detailed information about the structure and position of objects, enabling more advanced analysis and understanding by computer vision models.

The Image Annotation Process
The image annotation process involves several steps, starting from selecting the right data sources to establishing clear annotation guidelines and performing the actual annotation. Here are the key steps:
- Data Source Selection: Choose the right data sources to ensure that the dataset is representative of the problem domain. Sources can include public datasets, using free tools for scraping, or proprietary channels.
- Data Preprocessing: Once the images are collected, preprocess them to ensure consistency and quality. This may involve resizing images, removing duplicates, and filtering out irrelevant or low-quality images.
- Annotation Guidelines: Establish clear annotation guidelines to ensure consistency across annotations. These guidelines define the labeling conventions, specify the level of detail required, and address potential challenges or ambiguities.
- Annotation Process: The annotation process can be performed manually by human annotators or semi-automatically using machine learning techniques. Manual annotation involves trained individuals meticulously labeling images, while semi-automatic approaches leverage pre-trained models to generate initial annotations, which are then refined by human annotators.
Challenges in Image Annotation
Image annotation is not without its challenges. Annotators often face the following difficulties during the annotation process:
- Automated vs. Human Annotation: Choosing between automated annotation methods and human annotators is a trade-off between speed and accuracy. Automated methods may be quicker and less costly, but they may lack the precision and accuracy of human annotation.
- Ensuring High-Quality and Consistent Data: High-quality training data is essential for accurate ML models. Maintaining consistency across annotations can be challenging, especially when dealing with subjective data or when working with annotators from different cultural backgrounds. Different annotators may have varying interpretations of objects or regions within an image, leading to inconsistent annotations. To overcome this challenge, clear annotation guidelines and regular communication between annotators are crucial. Providing examples and reference images can help establish a common understanding and minimize subjectivity.
- Data Bias and Imbalance: Data bias and imbalance can significantly impact the performance and accuracy of computer vision models. Biased or imbalanced datasets can lead to skewed predictions and poor generalization. To overcome this challenge, careful dataset curation is essential. Ensuring diversity in the annotated data, addressing bias through augmentation techniques, and regularly monitoring and re-evaluating the dataset can help mitigate data bias and imbalance.
Image Annotation Best Practices
To ensure high-quality image annotation and improve the performance of ML models, it is essential to follow these best practices:
- Clear Annotation Guidelines: Establish comprehensive annotation guidelines that define annotation types, formats, and any specific instructions. Consistency in annotations is crucial for model training.
- Quality Over Quantity: Prioritize quality annotations over a large quantity of data. Accurate annotations on a smaller dataset often yield better results than hasty annotations on a larger dataset. One anomaly could really hamper your model.
- Expert Annotators: Employ annotators with domain expertise whenever possible. Their understanding of the subject matter can lead to more accurate and meaningful annotations.
- Iterative Feedback Loop: Maintain a feedback loop between annotators and data scientists. Regular communication helps clarify doubts, address challenges, and refine the annotation process.
- Label Consistency: Ensure consistent labeling across images. Ambiguous or inconsistent annotations can confuse the model and lead to reduced accuracy.
- Label Occuled objects: Picture this: an object peeking out from behind another, or just a glimpse of its edges. These are occluded objects—those that lie beyond the visible. Despite their partial invisibility, these objects hold equal importance. When multiple occluded objects overlap, it’s okay for bounding boxes to overlap too. The goal is accuracy, not neatness. Annotating each object fully, even when they share space, is key.
- Bounding Box Placement: For object detection tasks, place bounding boxes tightly around objects of interest without cropping or including irrelevant backgrounds. This helps the model learn object boundaries accurately.
- Multiple Perspectives: Annotate objects from different angles, viewpoints, and lighting conditions. This enables the model to generalize better and recognize objects under varying circumstances.
Sounds tedious? Let us handle this for you
Remember, effective image annotation directly influences the quality of your machine learning model’s training data, so investing time and effort into these best practices is crucial for achieving optimal results.
TL;DR of Image Annotation
Mastering image annotation is crucial for enhancing the accuracy of computer vision models. By following best practices such as using tight bounding boxes, maintaining consistency, and providing clear labeling instructions, you can improve the quality of your training data and optimize the performance of your ML models. Image annotation continues to play a vital role in the advancement of computer vision and AI, enabling machines to understand and interpret visual data effectively. With the right annotation techniques and practices, you can unlock the full potential of computer vision and drive innovation in various industries.


